Tabela de encaminhamento dinâmico (Dynamic Routing Table - DRT)
The DRT is a novel concept utilized in swarm technology to maintain P2P connections. In this approach, group members establish a graph of nodes, each identified by a unique hash, and these nodes must be interconnected.
Therefore, a structural framework is required that accomplishes the following objectives:
Maximiza o número de nós ligados em qualquer altura.
Minimiza os tempos de transmissão de mensagens.
Reduz o número de ligações entre pares.
Requer recursos computacionais mínimos.
Foram propostas várias soluções para atingir estes objetivos:
Each node is connected to the next node, resulting in only \(N\) connections. However, this approach is not efficient for transmitting messages since the message must traverse all peers one by one.
Every node is connected to all other nodes, leading to \(N^2\) connections. This configuration is effective for message transmission but demands more resources. This option will be selected for the first version.
Uma solução alternativa é apresentada no artigo intitulado Maximizing the Coverage of Roadmap Graph for Optimal Motion Planning, que oferece uma cobertura ideal de planejamento de movimento, mas exige cálculos computacionais significativos.
Utilizing the DHT algorithm for the routing table, which effectively addresses all four points and is already employed by Jami in their UDP implementation.
Além disso, para otimizar o número de soquetes, um soquete será alocado por um ConnectionManager para permitir a multiplexação de soquetes com um hash específico. Isso significa que, se houver necessidade de transmitir vários arquivos e participar de um bate-papo com alguém, apenas um soquete será utilizado.
Definições
Anotações:
\(n\): Node identifier
\(N\): Number of nodes in the network
\(b\): Configuration parameter
Termos e conceitos:
Mobile node / nó móvel: alguns dispositivos na rede podem estabelecer uma conetividade dinâmica, permitindo-lhes ligar-se e desligar-se rapidamente para otimizar a utilização da bateria. Em vez de manter um socket ponto-a-ponto dedicado com estes dispositivos, o protocolo opta por utilizar sockets existentes, se disponíveis, ou baseia-se em notificações push para transmitir informações. Esses nós são marcados com um sinalizador dedicado no protocolo.
Bucket: esta classe é utilizada para manipular e armazenar ligações e para gerir o estado dos nós (em ligação, conhecidos, móveis). Os nós conhecidos são utilizados quando a ligação com um nó fica offline.
Routing table / tabela de encaminhamento: ele é empregado para organizar os compartimentos, permitindo a busca dos nós mais próximos e estabelecendo o vínculo entre o gerenciador de enxames e a DRT (tabela de roteamento distribuído).
Swarm manager / gestor de enchames: este componente é responsável pela gestão da lógica interna e pelo controlo da distribuição das ligações na rede.
Swarm protocol / protocolo enxame: é utilizado para o intercâmbio de dados entre pares. Podem ser trocados os seguintes tipos de dados:
Pedido (por exemplo, FIND): Query | num | nodeId
Resposta (por exemplo, FOUND): Query | nodes | mobileNodes
Mensagem: Version | isMobile | Request or Response
Comparação de algoritmos
Chord
In a Chord network, each node is associated with a unique key computed using either the SHA-1 or the MD5 hash function. The nodes are organized into a ring in increasing order, and each node maintains a routing table that stores information about its nearest nodes. Each entry \(i\) in the routing table contains nodes with keys such that \(\mathrm{hash} = (n + 2i - 1) \mod 2^m\), where \(m\) represents the number of bits in the key.
Cada nó tem conhecimento dos seus sucessores e predecessores na rede Chord.
Para recuperar dados, um nó envia um pedido ao seu sucessor imediato. Se o nó possuir a chave necessária, responde; caso contrário, reencaminha o pedido para o seu próprio sucessor.
Ao adicionar um novo nó à rede, o nó transmite mensagens aos outros nós para atualizar as suas tabelas de encaminhamento e garantir uma integração adequada.
Se um nó ficar offline, deve atualizar a sua tabela de encaminhamento para reencaminhar o tráfego através de outros nós disponíveis.
The distance between two nodes is: \(d(n_1,n_2) = (n_2-n_1) \mod 2b\)
The routing table size is: \(\log(N)\)
The number of hops to get a value is: \(\log(N)\)
Sources:
Liben-Nowell, David; Balakrishnan, H.; Karger, David R. “Analysis of the evolution of peer-to-peer systems.” ACM SIGACT-SIGOPS Symposium on Principles of Distributed Computing (2002).
Liben-Nowell, David, Balakrishnan, H.; Karger, David R. “Observations on the Dynamic Evolution of Peer-to-Peer Networks.” International Workshop on Peer-to-Peer Systems (2002).
Stoica, Ion; Morris, Robert Tappan; Karger, David R; Kaashoek, M. Frans; Balakrishnan, H. “Chord: A scalable peer-to-peer lookup service for internet applications.” Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication (2001).
Pastry
In a Pastry network, each node is associated with a 128-bit identifier generated from a hashing function. Pastry is commonly used with IP addresses, and nodes are organized in a ring with increasing order. The routing table is divided into segments, typically determined by \(128 / 2b\), where \(b\) is typically set to \(4\), and IP addresses are placed within these segments.
Quando uma mensagem tem de ser transmitida a um nó folha, é enviada diretamente para o destinatário pretendido. Se a mensagem não se destinar a um nó folha, a rede tenta localizar o nó mais próximo e reencaminha os dados para esse nó para posterior transmissão.
Distance is: \(d(n_1,n_2) = (\mathrm{prefix}(n_2) - \mathrm{prefix}(n_1)) \mod 2b\)
Size of the routing table: \((2b - 1)\log_{2}(N)\)
Number of hops to get a value: \(\log_{2}(N)\)
where \(b\) is generally \(2\).
Sources:
Tirée de Castro, Miguel; Druschel, Peter; Hu, Y. Charlie; and Rowstron, Antony Ian Taylor. “Exploiting network proximity in peer-to-peer overlay networks.” (2002).
Kademlia
The Kademlia network algorithm is used by BitTorrent and Ethereum networks. In this scheme, each node is assigned a 160-bit identifier, and nodes can be organized in a ring with increasing order. Data is stored in the nearest nodes. However, the routing table employs a binary tree structure with \(k\)-buckets (where \(k\) represents the number of nodes in each bucket) to store information about the nearest nodes.
Quando um nó se liga à DHT (Distributed Hash Table), tenta preencher a tabela de encaminhamento, inserindo os nós descobertos nos buckets apropriados. Se um bucket ficar cheio, um nó pode ser ignorado se estiver demasiado distante; no entanto, se o bucket representar o mais próximo disponível, será dividido em dois para acomodar o novo nó. Quando um novo nó é adicionado, a sua tabela de encaminhamento é consultada para obter informações sobre os nós mais próximos.
Para obter um valor específico, um nó envia um pedido ao nó mais próximo com o hash correspondente.
Distance is \(d(n_1, n_2) = n_1 \oplus n_2\)
Size of the routing table: \(K \log_{2}(N)\)
Number of hops: \(\log_{2}(N)\)
Implementação
Ao iniciar o Jami, cada conversa inicia a criação de sua tabela de roteamento. A etapa inicial é estabelecer contato com um primeiro nó para iniciar a sincronização com outros nós. Esse processo é conhecido como “bootstrapping” e consiste em duas partes principais.
The first part involves retrieving all known devices in a conversation. This is accomplished by checking for known certificates in the repository or verifying the presence of certain members on the DHT (Distributed Hash Table). If a TCP connection already exists with any device in the conversation, it will be utilized. Additionally, known nodes are injected into the routing table. If no connection is successful, attempts to find new devices by performing a “GET” request on the DHT to get devices for each member.
A tabela de encaminhamento é posteriormente atualizada sempre que ocorre um evento num nó.
During routing table updates, the component will attempt to establish connections with new nodes if necessary. The decision to connect to new nodes is determined by the following conditions:
For the nearest bucket, a connection attempt is made if \((\mathrm{maxSize}(\mathrm{bucket}) - \mathrm{connectedNodes} - \mathrm{connectingNodes}) > 0\).
For other buckets, a connection is initiated if \((\mathrm{maxSize}(\mathrm{bucket}) - \mathrm{connectingNodes}) > 0\).
A distinção está no fato de que, no caso do compartimento mais próximo, o objetivo é tentar dividir os compartimentos, se necessário, enquanto compensa as desconexões em outros compartimentos. Isso é essencial para manter o conhecimento dos nós mais próximos.
Após a ligação a um novo nó, é enviado um pedido “FIND” para descobrir novos identificadores nas proximidades e identificar todos os nós móveis. Posteriormente, é enviado um pedido “FIND” de dez em dez minutos para manter a tabela de encaminhamento atualizada.
A classe principal responsável por este processo na base de código é o SwarmManager, e a fase de arranque é tratada na secção de conversação.
Arquitetura
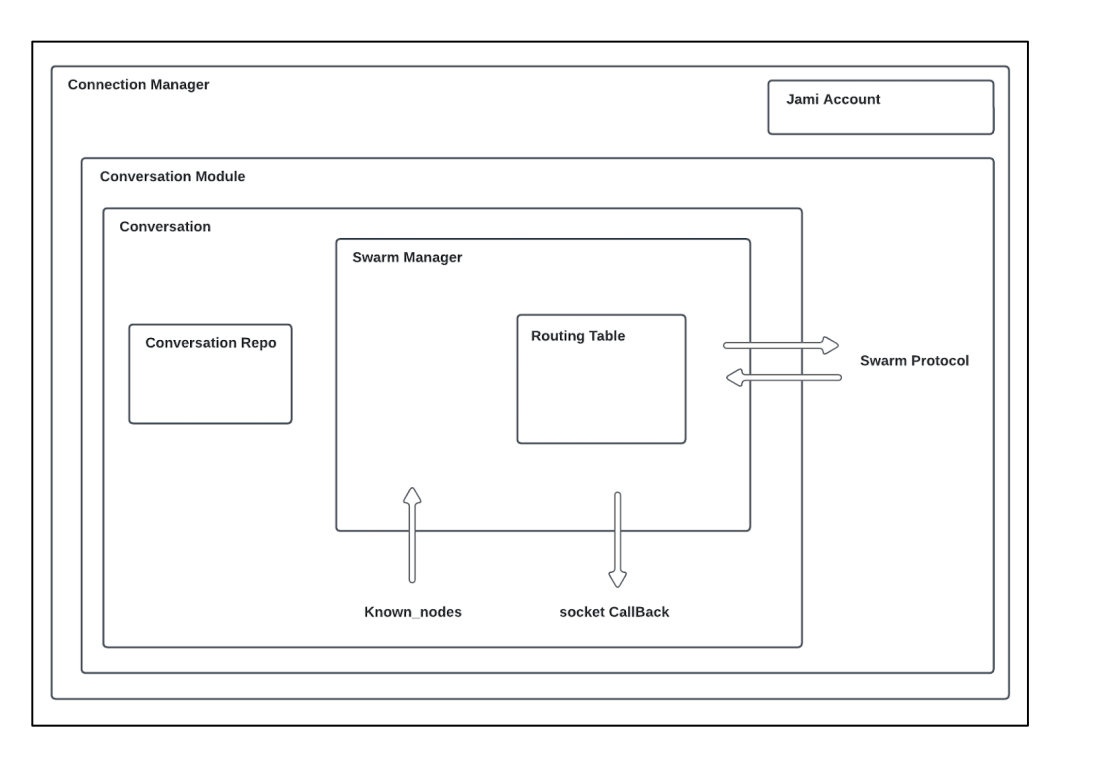
Performance analysis
Ferramentas
To validate the implementation and performance of the DRT component, several tools have been developed and are located in daemon/tests/unitTest/swarm, including swarm_spread, bootstrap, and more.
To interpret the results, the following tools are utilized:
gcovpara a análise da cobertura dos testes.ASanpara verificar se há fugas de memória e transbordamentos de heap.gdbpara depuração de estruturas internas.
While the major focus is on unit tests, for performance analysis, swarm_spread is relied on to assess various aspects, including:
O número de saltos necessários para a transmissão da mensagem.
O número de mensagens recebidas por nó.
Determinação das mensagens máximas e mínimas recebidas por cada nó.
Cálculo das iterações necessárias para transmitir uma mensagem a todos os nós.
Medição dos tempos de receção de mensagens.
Resultados
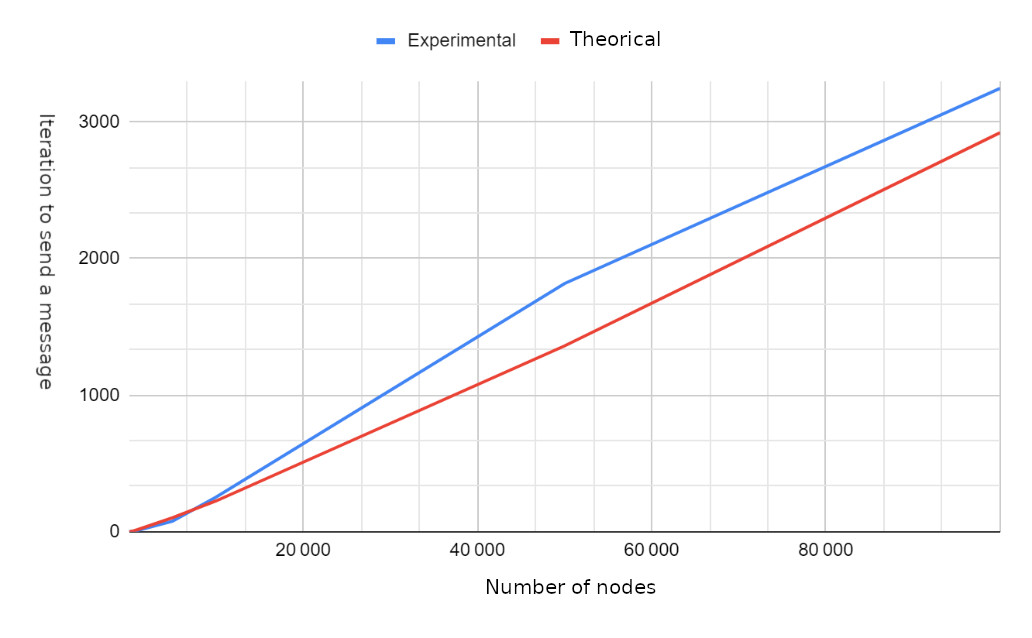
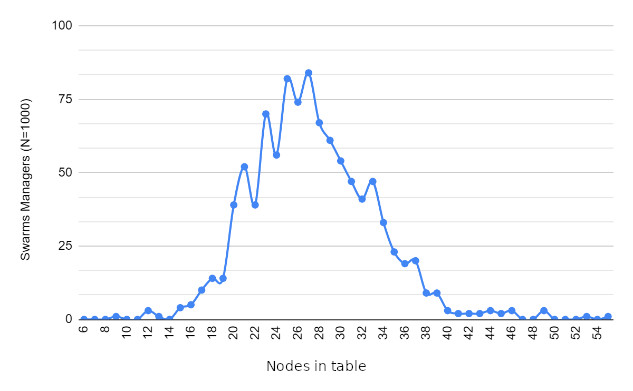
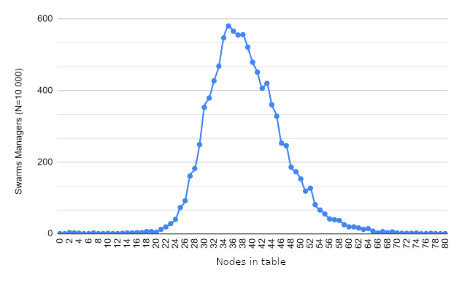
Trabalho futuro
Dynamic bucket size limit to get different bucket sizes depending on the size of the routing table.
Declining some connections to speed up the transmission a bit.