Dynamic Routing Table (DRT)
The DRT is a novel concept utilized in swarm technology to maintain P2P connections. In this approach, group members establish a graph of nodes, each identified by a unique hash, and these nodes must be interconnected.
Therefore, a structural framework is required that accomplishes the following objectives:
Maximiser les nœuds connectés à chaque fois
Minimizes message transmission times.
Reduces the number of links between peers.
Requires minimal computational resources.
Plusieurs solutions ont été proposées pour atteindre ces objectifs :
Each node is connected to the next node, resulting in only \(N\) connections. However, this approach is not efficient for transmitting messages since the message must traverse all peers one by one.
Every node is connected to all other nodes, leading to \(N^2\) connections. This configuration is effective for message transmission but demands more resources. This option will be selected for the first version.
Une autre solution est présentée dans l’article intitulé [Maximizing the Coverage of Roadmap Graph for Optimal Motion Planning] (https://www.hindawi.com/journals/complexity/2018/9104720/), qui offre une couverture optimale de la planification des mouvements mais nécessite des calculs importants.
Utilizing the DHT algorithm for the routing table, which effectively addresses all four points and is already employed by Jami in their UDP implementation.
De plus, pour optimiser le nombre de sockets, un socket sera alloué par un ConnectionManager pour permettre le multiplexage des sockets avec un hash spécifique. Cela signifie que s’il est nécessaire de transmettre plusieurs fichiers et d’engager une discussion avec quelqu’un, un seul socket sera utilisé.
Définitions
Notations:
\(n\): Node identifier
\(N\): Number of nodes in the network
\(b\): Configuration parameter
Terms and Concepts:
Nœud mobile : Certains appareils du réseau peuvent établir une connectivité dynamique, ce qui leur permet de se connecter et de se déconnecter rapidement afin d’optimiser l’utilisation de la batterie. Au lieu de maintenir une socket peer-to-peer dédiée avec ces appareils, le protocole choisit d’utiliser les sockets existants s’ils sont disponibles ou de s’appuyer sur les notifications push pour transmettre des informations. Ces nœuds sont marqués d’un drapeau dédié dans le protocole.
Bucket : Cette classe est utilisée pour manipuler et stocker les connexions et pour gérer l’état des nœuds (connectés, connus, mobiles). Les nœuds connus sont utilisés lorsque la connexion avec un nœud est coupée.
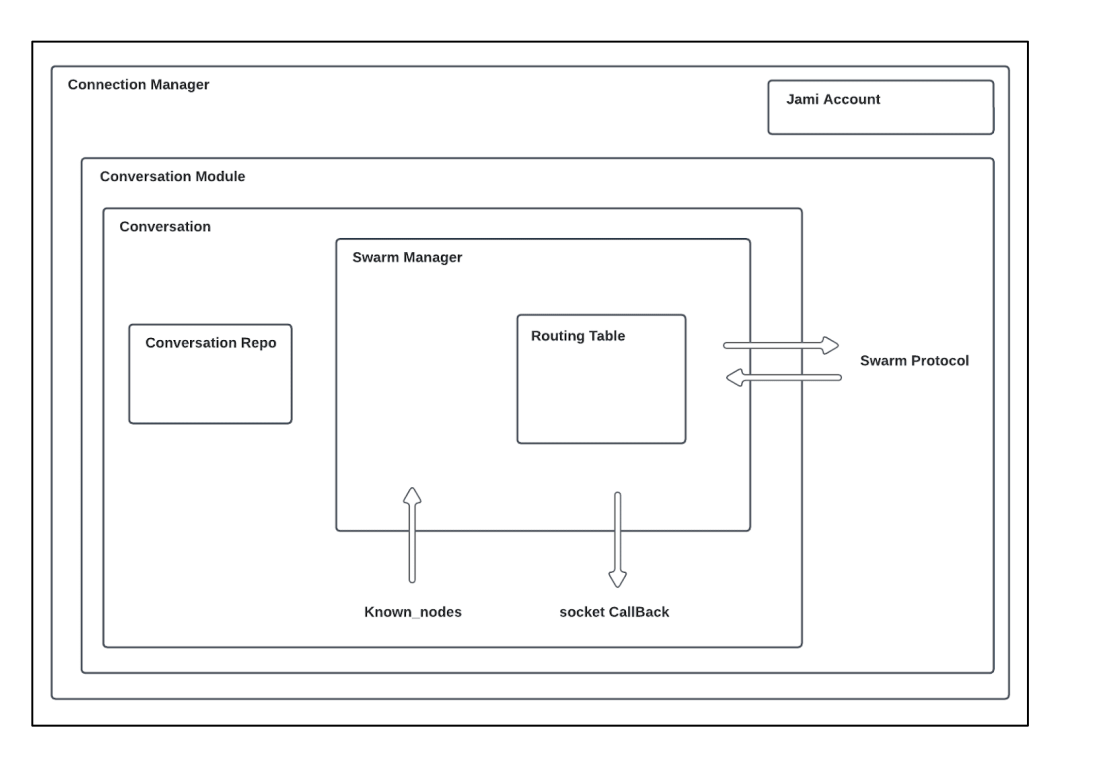
Table de routage : Elle est utilisée pour organiser les godets, permettre la recherche des nœuds les plus proches et établir le lien entre le gestionnaire de l’essaim et la table de routage distribuée (DRT).
Gestionnaire de l’essaim : Cette composante est chargée de gérer la logique interne et de superviser la distribution des connexions au sein du réseau.
Protocole d’essaimage (Swarm protocol) : Il est utilisé pour l’échange de données entre pairs. Les types de données suivants peuvent être échangés :
Request (e.g., FIND): Query | num | nodeId
Response (e.g., FOUND): Query | nodes | mobileNodes
Message: Version | isMobile | Request or Response
Algorithms comparison
Chord
In a Chord network, each node is associated with a unique key computed using either the SHA-1 or the MD5 hash function. The nodes are organized into a ring in increasing order, and each node maintains a routing table that stores information about its nearest nodes. Each entry \(i\) in the routing table contains nodes with keys such that \(\mathrm{hash} = (n + 2i - 1) \mod 2^m\), where \(m\) represents the number of bits in the key.
Chaque nœud connaît ses successeurs et ses prédécesseurs dans le réseau Chord.
Pour récupérer des données, un nœud envoie une demande à son successeur immédiat. Si le nœud possède la clé requise, il répond ; sinon, il transmet la demande à son propre successeur.
Lors de l’ajout d’un nouveau nœud au réseau, le nœud diffuse des messages aux autres nœuds afin de mettre à jour leurs tables de routage et d’assurer une intégration correcte.
If a node goes offline, it must update its routing table to reroute traffic through other available nodes.
The distance between two nodes is: \(d(n_1,n_2) = (n_2-n_1) \mod 2b\)
The routing table size is: \(\log(N)\)
The number of hops to get a value is: \(\log(N)\)
Sources:
Liben-Nowell, David; Balakrishnan, H.; Karger, David R. “Analysis of the evolution of peer-to-peer systems.” ACM SIGACT-SIGOPS Symposium on Principles of Distributed Computing (2002).
Liben-Nowell, David, Balakrishnan, H.; Karger, David R. “Observations on the Dynamic Evolution of Peer-to-Peer Networks.” International Workshop on Peer-to-Peer Systems (2002).
Stoica, Ion; Morris, Robert Tappan; Karger, David R; Kaashoek, M. Frans; Balakrishnan, H. “Chord: A scalable peer-to-peer lookup service for internet applications.” Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication (2001).
Pastry
In a Pastry network, each node is associated with a 128-bit identifier generated from a hashing function. Pastry is commonly used with IP addresses, and nodes are organized in a ring with increasing order. The routing table is divided into segments, typically determined by \(128 / 2b\), where \(b\) is typically set to \(4\), and IP addresses are placed within these segments.
Lorsqu’un message doit être transmis à un nœud feuille, il est envoyé directement au destinataire prévu. Si le message n’est pas destiné à un nœud feuille, le réseau tente de localiser le nœud le plus proche et transmet les données à ce nœud pour la suite de la transmission.
Distance is: \(d(n_1,n_2) = (\mathrm{prefix}(n_2) - \mathrm{prefix}(n_1)) \mod 2b\)
Size of the routing table: \((2b - 1)\log_{2}(N)\)
Number of hops to get a value: \(\log_{2}(N)\)
where \(b\) is generally \(2\).
Sources:
Tirée de Castro, Miguel; Druschel, Peter; Hu, Y. Charlie; and Rowstron, Antony Ian Taylor. “Exploiting network proximity in peer-to-peer overlay networks.” (2002).
Kademlia
The Kademlia network algorithm is used by BitTorrent and Ethereum networks. In this scheme, each node is assigned a 160-bit identifier, and nodes can be organized in a ring with increasing order. Data is stored in the nearest nodes. However, the routing table employs a binary tree structure with \(k\)-buckets (where \(k\) represents the number of nodes in each bucket) to store information about the nearest nodes.
Lorsqu’un nœud se connecte à la DHT (Distributed Hash Table), il tente d’alimenter la table de routage en insérant les nœuds découverts dans les godets appropriés. Si un panier est plein, un nœud peut être ignoré s’il est trop éloigné ; cependant, si le panier représente le plus proche disponible, il sera divisé en deux pour accueillir le nouveau nœud. Lorsqu’un nouveau nœud est ajouté, sa table de routage est interrogée pour obtenir des informations sur les nœuds les plus proches.
Pour récupérer une valeur spécifique, un nœud envoie une demande au nœud le plus proche possédant le hachage correspondant.
Distance is \(d(n_1, n_2) = n_1 \oplus n_2\)
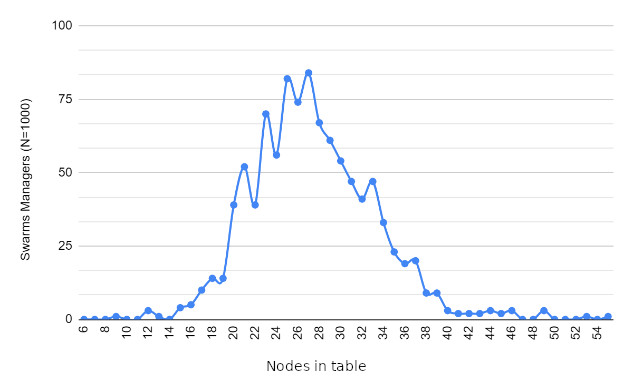
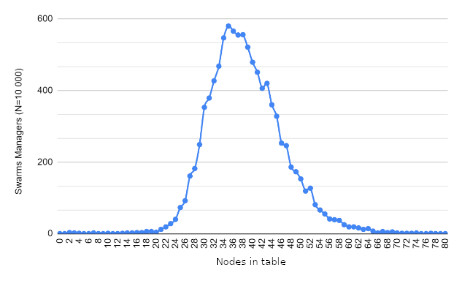
Size of the routing table: \(K \log_{2}(N)\)
Number of hops: \(\log_{2}(N)\)
Mise en œuvre
Au démarrage de Jami, chaque conversation initie la création de sa table de routage. L’étape initiale consiste à établir un contact avec un premier nœud pour commencer la synchronisation avec d’autres nœuds. Ce processus est connu sous le nom de « bootstrapping » et se compose de deux parties principales.
The first part involves retrieving all known devices in a conversation. This is accomplished by checking for known certificates in the repository or verifying the presence of certain members on the DHT (Distributed Hash Table). If a TCP connection already exists with any device in the conversation, it will be utilized. Additionally, known nodes are injected into the routing table. If no connection is successful, attempts to find new devices by performing a « GET » request on the DHT to get devices for each member.
La table de routage est ensuite mise à jour chaque fois qu’un événement se produit sur un nœud.
During routing table updates, the component will attempt to establish connections with new nodes if necessary. The decision to connect to new nodes is determined by the following conditions:
For the nearest bucket, a connection attempt is made if \((\mathrm{maxSize}(\mathrm{bucket}) - \mathrm{connectedNodes} - \mathrm{connectingNodes}) > 0\).
For other buckets, a connection is initiated if \((\mathrm{maxSize}(\mathrm{bucket}) - \mathrm{connectingNodes}) > 0\).
La distinction réside dans le fait que, dans le cas du seau le plus proche, l’objectif est de tenter de diviser les seaux si nécessaire tout en compensant les déconnexions dans d’autres seaux. Ceci est essentiel pour maintenir la connaissance des nœuds les plus proches.
Lors de la connexion à un nouveau nœud, une demande « FIND » est envoyée pour découvrir les nouveaux identifiants à proximité et identifier tous les nœuds mobiles. Par la suite, une demande « FIND » est envoyée toutes les dix minutes pour maintenir la table de routage à jour.
La classe principale responsable de ce processus dans la base de code est SwarmManager, et la phase d’amorçage est gérée dans la section de la conversation.
Architecture
Performance analysis
Tools
To validate the implementation and performance of the DRT component, several tools have been developed and are located in daemon/tests/unitTest/swarm, including swarm_spread, bootstrap, and more.
To interpret the results, the following tools are utilized:
gcovfor test coverage analysis.ASanto check for memory leaks and heap overflows.gdbfor debugging internal structures.
While the major focus is on unit tests, for performance analysis, swarm_spread is relied on to assess various aspects, including:
The number of hops required for message transmission.
The number of messages received per node.
Determining the maximum and minimum messages received by each node.
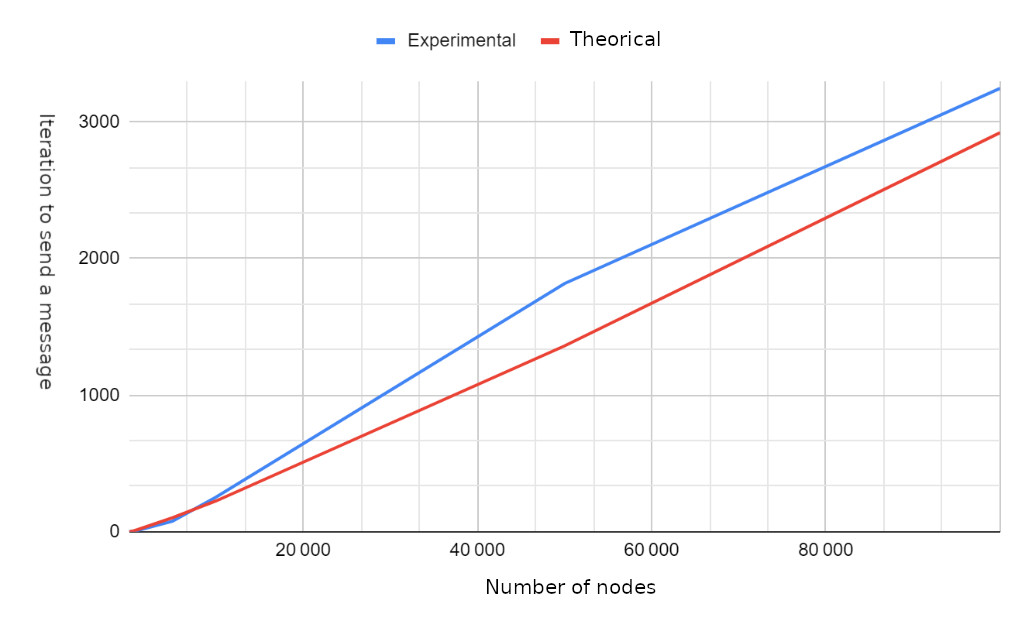
Calculating the iterations needed to transmit a message to all nodes.
Measuring message reception times.
Results
Future work
Dynamic bucket size limit to get different bucket sizes depending on the size of the routing table.
Declining some connections to speed up the transmission a bit.