Dynamiczna tabela routingu (DRT)
The DRT is a novel concept utilized in swarm technology to maintain P2P connections. In this approach, group members establish a graph of nodes, each identified by a unique hash, and these nodes must be interconnected.
Therefore, a structural framework is required that accomplishes the following objectives:
Maksymalizuje liczbę połączonych węzłów przez cały czas.
Minimalizuje czas przesyłania wiadomości.
Zmniejsza liczbę połączeń między urządzeniami równorzędnymi.
Wymaga minimalnych zasobów obliczeniowych.
Zaproponowano kilka rozwiązań, aby osiągnąć te cele:
Each node is connected to the next node, resulting in only \(N\) connections. However, this approach is not efficient for transmitting messages since the message must traverse all peers one by one.
Every node is connected to all other nodes, leading to \(N^2\) connections. This configuration is effective for message transmission but demands more resources. This option will be selected for the first version.
Alternatywne rozwiązanie przedstawiono w artykule zatytułowanym [Maximizing the Coverage of Roadmap Graph for Optimal Motion Planning] (https://www.hindawi.com/journals/complexity/2018/9104720/), który oferuje optymalne pokrycie planowania ruchu, ale wymaga znacznych obliczeń.
Utilizing the DHT algorithm for the routing table, which effectively addresses all four points and is already employed by Jami in their UDP implementation.
Dodatkowo, aby zoptymalizować liczbę gniazd, gniazdo zostanie przydzielone przez ConnectionManager, aby umożliwić multipleksowanie gniazd z określonym hashem. Oznacza to, że jeśli istnieje potrzeba przesłania wielu plików i zaangażowania się w czat z kimś, wykorzystane zostanie tylko jedno gniazdo.
Definicje
Uwagi:
\(n\): Node identifier
\(N\): Number of nodes in the network
\(b\): Configuration parameter
Terminy i pojęcia:.
Węzeł mobilny: Niektóre urządzenia w sieci mogą nawiązywać dynamiczną łączność, umożliwiając im szybkie łączenie się i rozłączanie w celu optymalizacji zużycia baterii. Zamiast utrzymywać dedykowane gniazdo peer-to-peer z tymi urządzeniami, protokół decyduje się na użycie istniejących gniazd, jeśli są dostępne, lub polega na powiadomieniach push do przesyłania informacji. Węzły te są oznaczone dedykowaną flagą w protokole.
Bucket: Ta klasa jest używana do manipulowania i przechowywania połączeń oraz do zarządzania stanem węzłów (łączenie, znane, mobilne). Znane węzły są używane, gdy połączenie z węzłem zostanie przerwane.
Tabela routingu: Służy do organizowania kubełków, umożliwiając wyszukiwanie najbliższych węzłów i ustanawiając połączenie między menedżerem roju a DRT (Distributed Routing Table).
Swarm Manager: Ten komponent jest odpowiedzialny za zarządzanie wewnętrzną logiką i nadzorowanie dystrybucji połączeń w sieci.
Swarm Protocol: Służy do wymiany danych między urządzeniami równorzędnymi. Wymieniane mogą być następujące typy danych:
Zapytanie (np. FIND): Query | num | nodeId
Odpowiedź (np. FOUND): Query | nodes | mobileNodes
Wiadomość: Wersja | isMobile | Zapytanie lub Odpowiedź
Porównanie algorytmów
Chord
In a Chord network, each node is associated with a unique key computed using either the SHA-1 or the MD5 hash function. The nodes are organized into a ring in increasing order, and each node maintains a routing table that stores information about its nearest nodes. Each entry \(i\) in the routing table contains nodes with keys such that \(\mathrm{hash} = (n + 2i - 1) \mod 2^m\), where \(m\) represents the number of bits in the key.
Każdy węzeł jest świadomy swoich następców i poprzedników w sieci Chord.
Aby pobrać dane, węzeł wysyła żądanie do swojego bezpośredniego następcy. Jeśli węzeł posiada wymagany klucz, odpowiada; w przeciwnym razie przekazuje żądanie do swojego następcy.
Podczas dodawania nowego węzła do sieci, węzeł rozgłasza wiadomości do innych węzłów, aby zaktualizować ich tabele routingu i zapewnić prawidłową integrację.
Jeśli węzeł przejdzie w tryb offline, musi zaktualizować swoją tabelę routingu, aby przekierować ruch przez inne dostępne węzły.
The distance between two nodes is: \(d(n_1,n_2) = (n_2-n_1) \mod 2b\)
The routing table size is: \(\log(N)\)
The number of hops to get a value is: \(\log(N)\)
Sources:
Liben-Nowell, David; Balakrishnan, H.; Karger, David R. “Analysis of the evolution of peer-to-peer systems.” ACM SIGACT-SIGOPS Symposium on Principles of Distributed Computing (2002).
Liben-Nowell, David, Balakrishnan, H.; Karger, David R. “Observations on the Dynamic Evolution of Peer-to-Peer Networks.” International Workshop on Peer-to-Peer Systems (2002).
Stoica, Ion; Morris, Robert Tappan; Karger, David R; Kaashoek, M. Frans; Balakrishnan, H. “Chord: A scalable peer-to-peer lookup service for internet applications.” Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication (2001).
Pastry
In a Pastry network, each node is associated with a 128-bit identifier generated from a hashing function. Pastry is commonly used with IP addresses, and nodes are organized in a ring with increasing order. The routing table is divided into segments, typically determined by \(128 / 2b\), where \(b\) is typically set to \(4\), and IP addresses are placed within these segments.
Gdy wiadomość musi zostać przesłana do węzła-liścia, jest ona wysyłana bezpośrednio do zamierzonego odbiorcy. Jeśli wiadomość nie jest przeznaczona dla węzła-liścia, sieć próbuje zlokalizować najbliższy węzeł i przekazuje dane do tego węzła w celu dalszej transmisji.
Distance is: \(d(n_1,n_2) = (\mathrm{prefix}(n_2) - \mathrm{prefix}(n_1)) \mod 2b\)
Size of the routing table: \((2b - 1)\log_{2}(N)\)
Number of hops to get a value: \(\log_{2}(N)\)
where \(b\) is generally \(2\).
Sources:
Tirée de Castro, Miguel; Druschel, Peter; Hu, Y. Charlie; and Rowstron, Antony Ian Taylor. “Exploiting network proximity in peer-to-peer overlay networks.” (2002).
Kademlia
The Kademlia network algorithm is used by BitTorrent and Ethereum networks. In this scheme, each node is assigned a 160-bit identifier, and nodes can be organized in a ring with increasing order. Data is stored in the nearest nodes. However, the routing table employs a binary tree structure with \(k\)-buckets (where \(k\) represents the number of nodes in each bucket) to store information about the nearest nodes.
Gdy węzeł łączy się z DHT (Distributed Hash Table), próbuje zapełnić tabelę routingu, wstawiając wykryte węzły do odpowiednich kubełków. Jeśli kubeł zostanie zapełniony, węzeł może zostać zignorowany, jeśli jest zbyt odległy; jeśli jednak kubeł reprezentuje najbliższy dostępny, zostanie podzielony na dwa, aby pomieścić nowy węzeł. Po dodaniu nowego węzła, jego tabela routingu jest sprawdzana w celu uzyskania informacji o najbliższych węzłach.
Aby pobrać określoną wartość, węzeł wysyła żądanie do najbliższego węzła z odpowiednim hashem.
Distance is \(d(n_1, n_2) = n_1 \oplus n_2\)
Size of the routing table: \(K \log_{2}(N)\)
Number of hops: \(\log_{2}(N)\)
Wdrożenie
Podczas uruchamiania Jami, każda konwersacja inicjuje tworzenie swojej tabeli routingu. Początkowym krokiem jest nawiązanie kontaktu z pierwszym węzłem, aby rozpocząć synchronizację z innymi węzłami. Proces ten znany jest jako „bootstrapping” i składa się z dwóch głównych części.
The first part involves retrieving all known devices in a conversation. This is accomplished by checking for known certificates in the repository or verifying the presence of certain members on the DHT (Distributed Hash Table). If a TCP connection already exists with any device in the conversation, it will be utilized. Additionally, known nodes are injected into the routing table. If no connection is successful, attempts to find new devices by performing a „GET” request on the DHT to get devices for each member.
Tabela routingu jest następnie aktualizowana za każdym razem, gdy w węźle wystąpi zdarzenie.
During routing table updates, the component will attempt to establish connections with new nodes if necessary. The decision to connect to new nodes is determined by the following conditions:
For the nearest bucket, a connection attempt is made if \((\mathrm{maxSize}(\mathrm{bucket}) - \mathrm{connectedNodes} - \mathrm{connectingNodes}) > 0\).
For other buckets, a connection is initiated if \((\mathrm{maxSize}(\mathrm{bucket}) - \mathrm{connectingNodes}) > 0\).
Różnica polega na tym, że w przypadku najbliższego zasobnika celem jest próba podzielenia zasobników, jeśli jest to wymagane, przy jednoczesnym kompensowaniu rozłączeń w innych zasobnikach. Jest to niezbędne do utrzymania wiedzy o najbliższych węzłach.
Po nawiązaniu połączenia z nowym węzłem wysyłane jest żądanie „FIND” w celu wykrycia nowych identyfikatorów w pobliżu i zidentyfikowania wszystkich węzłów mobilnych. Następnie żądanie „FIND” jest wysyłane co dziesięć minut, aby tabela routingu była aktualna.
Główną klasą odpowiedzialną za ten proces w bazie kodu jest SwarmManager, a faza bootstrapowania jest obsługiwana w sekcji konwersacji.
Architektura
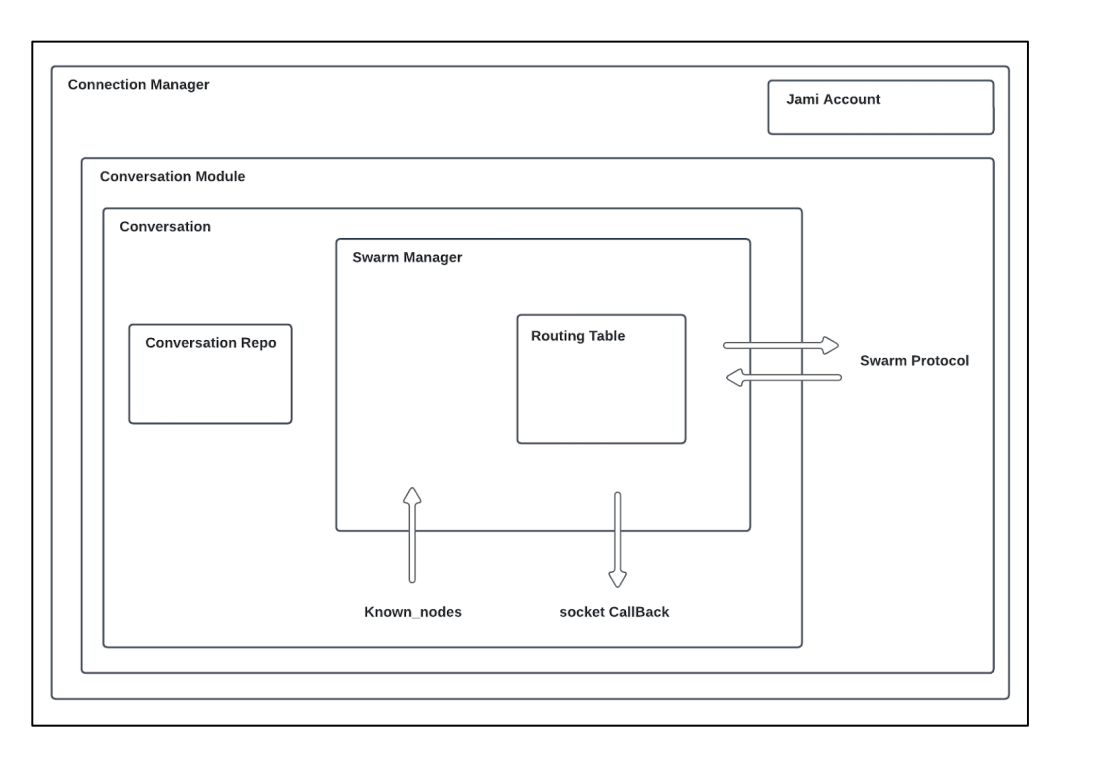
Performance analysis
Narzędzia
To validate the implementation and performance of the DRT component, several tools have been developed and are located in daemon/tests/unitTest/swarm, including swarm_spread, bootstrap, and more.
To interpret the results, the following tools are utilized:
gcovdo analizy pokrycia testowego.ASando sprawdzania wycieków pamięci i przepełnień sterty.gdbdo debugowania wewnętrznych struktur.
While the major focus is on unit tests, for performance analysis, swarm_spread is relied on to assess various aspects, including:
Liczba przeskoków wymaganych do transmisji wiadomości.
Liczba otrzymanych wiadomości na węzeł.
Określenie maksymalnej i minimalnej liczby wiadomości odebranych przez każdy węzeł.
Obliczanie iteracji potrzebnych do przesłania wiadomości do wszystkich węzłów.
Pomiar czasu odbierania wiadomości.
Wyniki
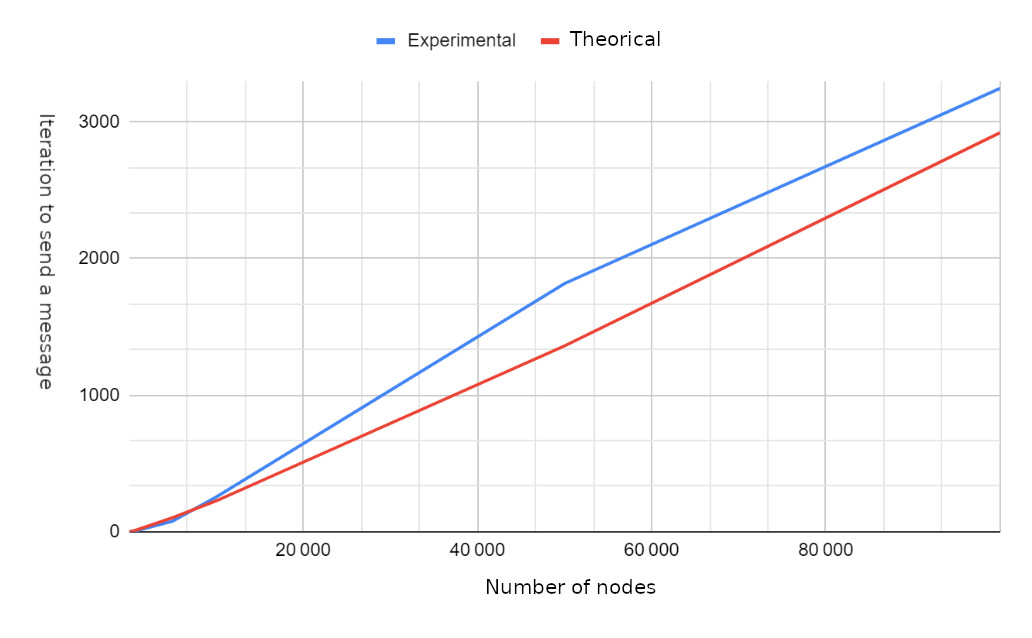
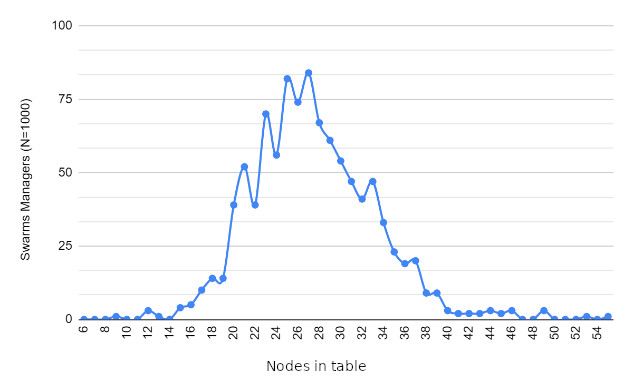
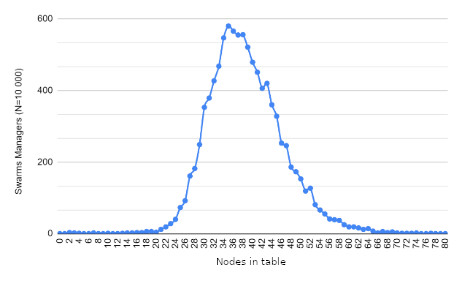
Przyszłe działania
Dynamic bucket size limit to get different bucket sizes depending on the size of the routing table.
Declining some connections to speed up the transmission a bit.