Dynamic Routing Table (DRT)
La DRT est un nouveau concept utilisé dans la technologie Swarm pour maintenir les connexions pair-à-pair (P2P). Dans cette approche, les membres du groupe établissent un graphe de nœuds, chacun identifié par un hachage unique, et ces nœuds doivent être interconnectés.
Nous avons donc besoin d’un cadre structurel qui permette d’atteindre les objectifs suivants :
Maximiser les nœuds connectés à chaque fois
Minimizes message transmission times.
Reduces the number of links between peers.
Requires minimal computational resources.
Plusieurs solutions ont été proposées pour atteindre ces objectifs :
Chaque nœud est connecté au nœud suivant, ce qui donne seulement « N » connexions. Toutefois, cette approche n’est pas efficace pour la transmission de messages, car le message doit traverser tous les pairs un par un.
Chaque nœud est connecté à tous les autres nœuds, ce qui conduit à des connexions « N x N ». Cette configuration est efficace pour la transmission de messages mais demande plus de ressources. **Cette option sera sélectionnée pour la première version.
Une autre solution est présentée dans l’article intitulé [Maximizing the Coverage of Roadmap Graph for Optimal Motion Planning] (https://www.hindawi.com/journals/complexity/2018/9104720/), qui offre une couverture optimale de la planification des mouvements mais nécessite des calculs importants.
L’utilisation de l’algorithme DHT (Distributed Hash Table) pour la table de routage, qui répond efficacement aux quatre points et qui est déjà utilisé par Jami dans sa mise en œuvre de l’UDP.
De plus, pour optimiser le nombre de sockets, un socket sera alloué par un ConnectionManager pour permettre le multiplexage des sockets avec un hash spécifique. Cela signifie que s’il est nécessaire de transmettre plusieurs fichiers et d’engager une discussion avec quelqu’un, un seul socket sera utilisé.
Définitions
Notations:
n: Node identifier
N: Number of nodes in the network
b: Configuration parameter
Terms and Concepts:
Nœud mobile : Certains appareils du réseau peuvent établir une connectivité dynamique, ce qui leur permet de se connecter et de se déconnecter rapidement afin d’optimiser l’utilisation de la batterie. Au lieu de maintenir une socket peer-to-peer dédiée avec ces appareils, le protocole choisit d’utiliser les sockets existants s’ils sont disponibles ou de s’appuyer sur les notifications push pour transmettre des informations. Ces nœuds sont marqués d’un drapeau dédié dans le protocole.
Bucket : Cette classe est utilisée pour manipuler et stocker les connexions et pour gérer l’état des nœuds (connectés, connus, mobiles). Les nœuds connus sont utilisés lorsque la connexion avec un nœud est coupée.
Table de routage : Elle est utilisée pour organiser les godets, permettre la recherche des nœuds les plus proches et établir le lien entre le gestionnaire de l’essaim et la table de routage distribuée (DRT).
Gestionnaire de l’essaim : Cette composante est chargée de gérer la logique interne et de superviser la distribution des connexions au sein du réseau.
Protocole d’essaimage (Swarm protocol) : Il est utilisé pour l’échange de données entre pairs. Les types de données suivants peuvent être échangés :
Request (e.g., FIND): Query | num | nodeId
Response (e.g., FOUND): Query | nodes | mobileNodes
Message: Version | isMobile | Request or Response
Algorithms comparison
Chord
Dans un réseau Chord, chaque nœud est associé à une clé unique calculée à l’aide des fonctions de hachage SHA-1 ou MD5. Les nœuds sont organisés en anneau par ordre croissant et chaque nœud maintient une table de routage qui stocke des informations sur les nœuds les plus proches. Chaque entrée i de la table de routage contient des nœuds avec des clés telles que \(hash = (n + 2i - 1) mod 2^m\), où m représente le nombre de bits dans la clé.
Chaque nœud connaît ses successeurs et ses prédécesseurs dans le réseau Chord.
Pour récupérer des données, un nœud envoie une demande à son successeur immédiat. Si le nœud possède la clé requise, il répond ; sinon, il transmet la demande à son propre successeur.
Lors de l’ajout d’un nouveau nœud au réseau, le nœud diffuse des messages aux autres nœuds afin de mettre à jour leurs tables de routage et d’assurer une intégration correcte.
If a node goes offline, it must update its routing table to reroute traffic through other available nodes.
The distance between two nodes is: \(d(n1,n2,) = (n1-n2) mod 2b`\)
The routing table size is: \(log{N}\)
The number of hops to get a value is: \(log{N}\)
Sources: (Stoica, Morris, Karger, Kaashoek & Balakrishnan, 2001). (Liben-Nowell, Balakrishnan & Karger, 2002).
Pastry
Dans un réseau Pastry, chaque nœud est associé à un identifiant de 128 bits généré à partir d’une fonction de hachage. Pastry est couramment utilisé avec des adresses IP, et les nœuds sont organisés en anneau dans un ordre croissant. La table de routage est divisée en segments, généralement déterminés par \(128 / 2b\), où \(b\) est généralement fixé à 4, et les adresses IP sont placées dans ces segments.
Lorsqu’un message doit être transmis à un nœud feuille, il est envoyé directement au destinataire prévu. Si le message n’est pas destiné à un nœud feuille, le réseau tente de localiser le nœud le plus proche et transmet les données à ce nœud pour la suite de la transmission.
La distance est : \(d(n1,n2,) = (prefix(n1) - prefix(n2)) mod 2b\)
Taille de la table de routage : \((2b - 1)log{_2}{N}\)
Number of hops to get a value: \(log{_2}{N}\)
where b is generally 2.
Sources: Tirée de Castro, Druschel, Hu, Rowstron (2002, p.3)21
Kademlia
Cet algorithme est utilisé par BitTorrent et Ethereum. Dans ce schéma, chaque nœud se voit attribuer un identifiant de 160 bits, et les nœuds peuvent être organisés en anneau par ordre croissant. Les données sont stockées dans les nœuds les plus proches. Cependant, la table de routage utilise une structure arborescente binaire avec k-buckets (où k représente le nombre de nœuds dans chaque bucket) pour stocker les informations sur les nœuds les plus proches.
Lorsqu’un nœud se connecte à la DHT (Distributed Hash Table), il tente d’alimenter la table de routage en insérant les nœuds découverts dans les godets appropriés. Si un panier est plein, un nœud peut être ignoré s’il est trop éloigné ; cependant, si le panier représente le plus proche disponible, il sera divisé en deux pour accueillir le nouveau nœud. Lorsqu’un nouveau nœud est ajouté, sa table de routage est interrogée pour obtenir des informations sur les nœuds les plus proches.
Pour récupérer une valeur spécifique, un nœud envoie une demande au nœud le plus proche possédant le hachage correspondant.
La distance est \(d(n1, n2,) = n1 XOR n2\)
Taille de la table de routage : \(K \times log{_2}{N}\)
Nombre de sauts : \(log{_2}{N}\)
où b est généralement égal à 1.
Mise en œuvre
Au démarrage de Jami, chaque conversation initie la création de sa table de routage. L’étape initiale consiste à établir un contact avec un premier nœud pour commencer la synchronisation avec d’autres nœuds. Ce processus est connu sous le nom de « bootstrapping » et se compose de deux parties principales.
La première partie consiste à retrouver tous les appareils connus dans une conversation. Pour ce faire, on recherche les certificats connus dans le référentiel ou on vérifie la présence de certains membres dans la DHT (Distributed Hash Table). Si une connexion TCP existe déjà avec un appareil de la conversation, elle sera utilisée. En outre, les nœuds connus sont injectés dans la table de routage.
La table de routage est ensuite mise à jour chaque fois qu’un événement se produit sur un nœud.
Lors des mises à jour de la table de routage, le composant tente d’établir des connexions avec de nouveaux nœuds si nécessaire. La décision de se connecter à de nouveaux nœuds est déterminée par les conditions suivantes : - Pour le seau le plus proche, une tentative de connexion est effectuée si \((maxSize(Bucket) - connected nodes - connecting nodes) > 0\). - Pour les autres godets, une connexion est initiée si \((maxSize(Bucket) - connecting nodes) > 0\).
La distinction réside dans le fait que, dans le cas du seau le plus proche, l’objectif est de tenter de diviser les seaux si nécessaire tout en compensant les déconnexions dans d’autres seaux. Ceci est essentiel pour maintenir la connaissance des nœuds les plus proches.
Lors de la connexion à un nouveau nœud, une demande « FIND » est envoyée pour découvrir les nouveaux identifiants à proximité et identifier tous les nœuds mobiles. Par la suite, une demande « FIND » est envoyée toutes les dix minutes pour maintenir la table de routage à jour.
La classe principale responsable de ce processus dans la base de code est SwarmManager, et la phase d’amorçage est gérée dans la section de la conversation.
Architecture
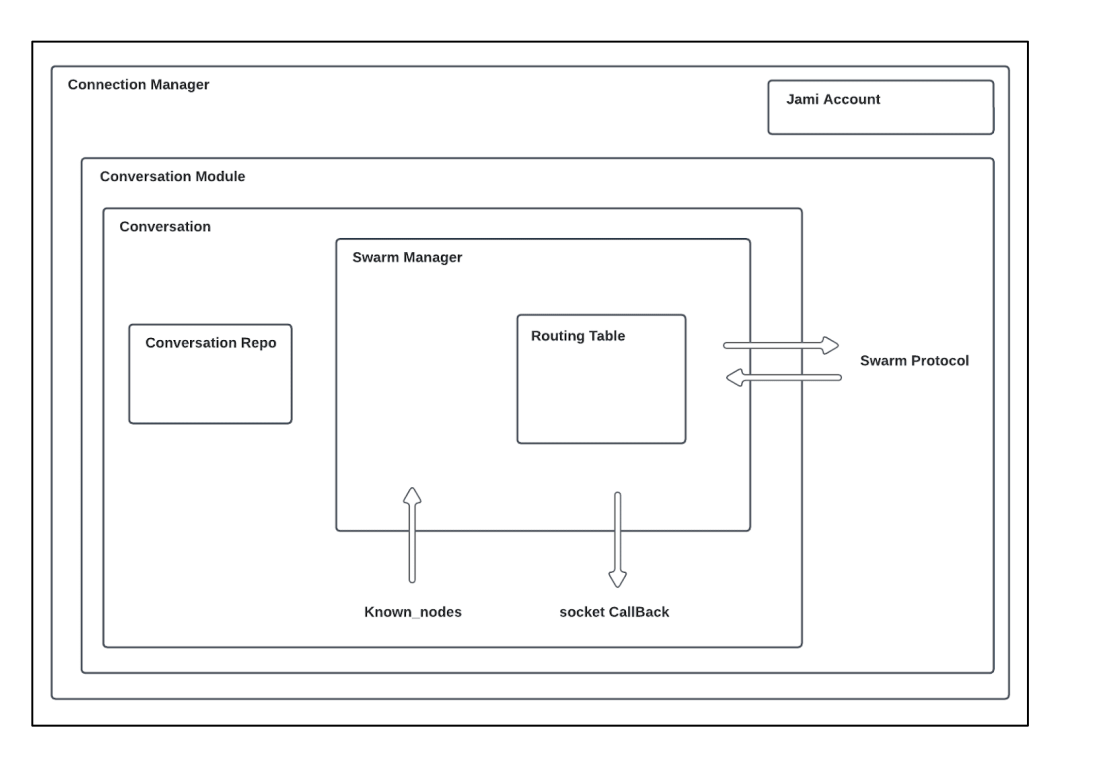
Perfomance analysis
Tools
Pour valider l’implémentation et les performances du composant DRT, nous avons développé plusieurs outils situés dans daemon/tests/unitTest/swarm, y compris swarm_spread, bootstrap, et plus encore.
To interpret the results, we utilize the following tools:
gcov for test coverage analysis.
ASan to check for memory leaks and heap overflows.
gdb for debugging internal structures.
While the major focus is on unit tests, for performance analysis, we rely on swarm_spread to assess various aspects, including:
The number of hops required for message transmission.
The number of messages received per node.
Determining the maximum and minimum messages received by each node.
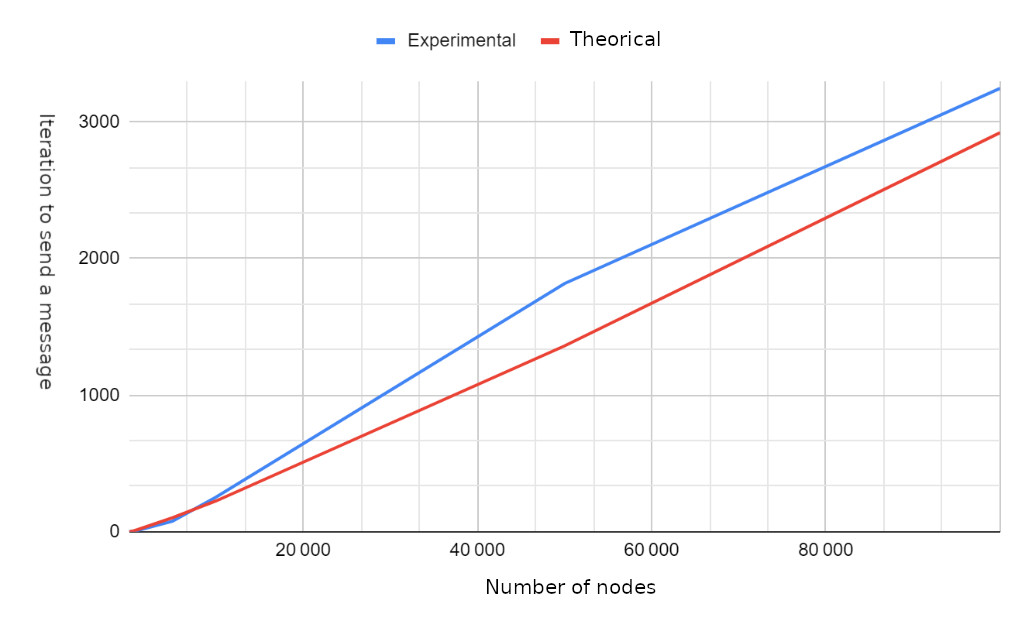
Calculating the iterations needed to transmit a message to all nodes.
Measuring message reception times.
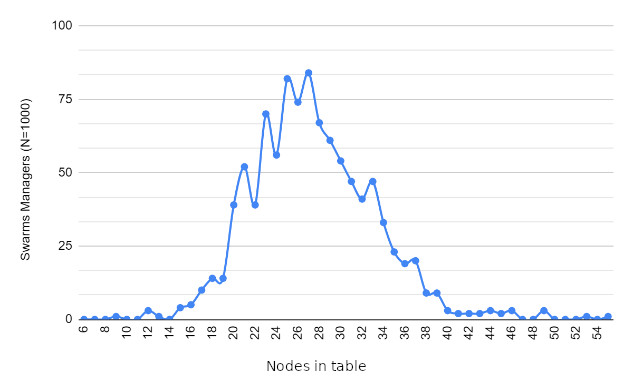
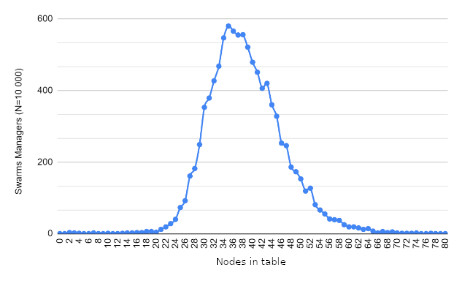
Results
Future work
Dynamic bucket size limit to get different bucket size depending on how large is the routing table
Declining some connections to speed-up the transmission a bit