Tabla de enrutamiento dinámico (DRT)
DRT es un concepto novedoso utilizado en la tecnología de enjambre para mantener las conexiones [P2P] (https://wikipedia.org/wiki/Peer-to-peer). En este enfoque, los miembros del grupo establecen un gráfico de nodos, cada uno identificado por un hash único, y estos nodos deben estar interconectados.
Por lo tanto, se requiere un marco estructural que logre los siguientes objetivos:
Maximiza el número de nodos conectados en todo momento.
Minimiza los tiempos de transmisión de mensajes.
Reduce el número de enlaces entre pares.
Requiere recursos computacionales mínimos.
Se han propuesto varias soluciones para lograr estos objetivos.
Cada nodo está conectado al siguiente nodo, lo que da como resultado solo conexiones \(N\). Sin embargo, este enfoque no es eficiente para transmitir mensajes, ya que el mensaje debe atravesar todos los pares uno por uno.
Cada nodo está conectado a todos los demás nodos, lo que lleva a \(N^2\) conexiones. Esta configuración es efectiva para la transmisión de mensajes, pero exige más recursos. Esta opción se seleccionará para la primera versión.
Una solución alternativa se presenta en el artículo titulado Maximizing the Coverage of Roadmap Graph for Optimal Motion Planning, que ofrece una cobertura óptima de planificación de movimiento pero requiere cálculos computacionales significativos.
Utilizando el algoritmo DHT para la tabla de enrutamiento, que aborda efectivamente los cuatro puntos y ya lo emplea Jami en su implementación de UDP.
Además, para optimizar el número de sockets, se asignará un socket por un ConnectionManager para permitir la multiplexación de sockets con un hash específico. Esto significa que si hay necesidad de transmitir múltiples archivos y entablar una conversación con alguien, solo se utilizará un socket.
Definiciones
Notaciones:
\(n\): Identificador de nodo
\(N\): Número de nodos en la red
\(b\): Parámetro de configuración
Términos y Conceptos:
Nodo móvil: Algunos dispositivos en la red pueden establecer una conectividad dinámica, lo que les permite conectarse y desconectarse rápidamente para optimizar el uso de la batería. En lugar de mantener un socket dedicado de igual a igual con estos dispositivos, el protocolo opta por utilizar sockets existentes si están disponibles o confía en las notificaciones push para transmitir información. Estos nodos están marcados con una bandera dedicada en el protocolo.
Bucket: Esta clase se utiliza para manipular y almacenar conexiones y para gestionar el estado de los nodos (conexión, conocido, móvil). Los nodos conocidos se utilizan cuando la conexión con un nodo se desconecta.
Tabla de enrutamiento: Se utiliza para organizar los buckets, permitiendo la búsqueda de nodos más cercanos y estableciendo el enlace entre el administrador del enjambre y la DRT (Tabla de enrutamiento distribuida).
Swarm Manager: Este componente es responsable de gestionar la lógica interna y supervisar la distribución de conexiones dentro de la red.
Protocolo Swarm: Se utiliza para el intercambio de datos entre pares. Se pueden intercambiar los siguientes tipos de datos:
Solicitud (por ejemplo, FIND): Consulta | num | nodeId
Respuesta (por ejemplo, FOUND): Consulta | nodos | nodos móviles
Mensaje: Versión | isMobile | Solicitud o Respuesta
Comparación de algoritmos
Chord
En una Red chord, cada nodo está asociado con una clave única calculada usando la función hash SHA-1 o [MD5] (https://wikipedia.org/wiki/MD5). Los nodos están organizados en un anillo en orden creciente, y cada nodo mantiene una tabla de enrutamiento que almacena información sobre sus nodos más cercanos. Cada entrada \(i\) en la tabla de enrutamiento contiene los nodos con las teclas tal que \(\mathrm{hash} = (n + 2i - 1) \mod 2^m\), donde \(m\) representa el número de bits de la clave.
Cada nodo es consciente de sus sucesores y predecesores en la red Chord.
Para recuperar datos, un nodo envía una solicitud a su sucesor inmediato. Si el nodo posee la clave requerida, responde; de lo contrario, reenvía la solicitud a su propio sucesor.
Cuando se agrega un nuevo nodo a la red, el nodo transmite mensajes a otros nodos para actualizar sus tablas de enrutamiento y garantizar una integración adecuada.
Si un nodo se desconecta, debe actualizar su tabla de enrutamiento para redirigir el tráfico a través de otros nodos disponibles.
La distancia entre dos nodos es: \(d(n_1,n_2) = (n_2-n_1) \mod 2b\)
El tamaño de la tabla de enrutamiento es: \(\log(N)\)
El número de saltos para obtener un valor es: \(\log(N)\)
Fuentes:
Liben-Nowell, David; Balakrishnan, H. ;Karger, David R. «Análisis de la evolución de los sistemas peer-to-peer.» Simposio ACM SIGACT-SIGOPS sobre Principios de Computación Distribuida (2002).
Liben - Nowell, David, Balakrishnan, H.; Karger, David R. «Observaciones sobre la Evolución Dinámica de las Redes Peer-to-Peer.» Taller Internacional sobre Sistemas Peer-to-Peer (2002).
Stoica, Ion; Morris, Robert Tappan; Karger, David R; Kaashoek, M. Frans; Balakrishnan, H. » Chord: Un servicio escalable de búsqueda punto a punto para aplicaciones de Internet.» Conferencia sobre Aplicaciones, Tecnologías, Arquitecturas y Protocolos para la Comunicación Informática (2001).
Pastry
En una Red pastry, cada nodo está asociado con un identificador de 128 bits generado a partir de una función hash. Pastry se usa comúnmente con direcciones IP, y los nodos se organizan en un anillo con un orden creciente. La tabla de enrutamiento se divide en segmentos, determinados normalmente por \(128 / 2b\), donde \(b\) se establece normalmente en \(4\), y las direcciones IP se colocan dentro de estos segmentos.
Cuando un mensaje necesita ser transmitido a un nodo hoja, se envía directamente al destinatario previsto. Si el mensaje no está destinado a un nodo hoja, la red intenta localizar el nodo más cercano y reenvía los datos a ese nodo para su posterior transmisión.
La distancia es: \(d(n_1,n_2) = (\mathrm{prefix}(n_2) - \mathrm{prefix}(n_1)) \mod 2b\)
Tamaño de la tabla de enrutamiento: \((2b - 1)\log_{2}(N)\)
Número de saltos para obtener un valor: \(\log_{2}(N)\)
donde \(b\) es generalmente \(2\).
Fuentes:
Titre de Castro, Miguel; Druschel, Peter; Hu, Y. Charlie; y Rowstron, Antony Ian Taylor. «Explotando la proximidad de la red en redes superpuestas de igual a igual.” (2002).
Kademlia
El algoritmo de la red Kademlia lo usan las redes [BitTorrent] (https://wikipedia.org/wiki/BitTorrent) y [Ethereum] (https://wikipedia.org/wiki/Ethereum). En este esquema, a cada nodo se le asigna un identificador de 160 bits, y los nodos se pueden organizar en un anillo con un orden creciente. Los datos se almacenan en los nodos más cercanos. Sin embargo, la tabla de enrutamiento emplea una estructura de árbol binario con \(k\) buckets (donde \(k\) representa el número de nodos en cada bucket) para almacenar información sobre los nodos más cercanos.
Cuando un nodo se conecta a la DHT (Tabla de Hash Distribuida), intenta poblar la tabla de enrutamiento insertando nodos descubiertos en los cubos apropiados. Si un cubo se llena, un nodo puede ser ignorado si está demasiado lejos; sin embargo, si el cubo representa el más cercano disponible, se dividirá en dos para acomodar el nuevo nodo. Cuando se agrega un nuevo nodo, se consulta su tabla de enrutamiento para obtener información sobre los nodos más cercanos.
Para recuperar un valor específico, un nodo envía una solicitud al nodo más cercano con el hash correspondiente.
La distancia es \(d(n_1, n_2) = n_1 \oplus n_2\)
Tamaño de la tabla de enrutamiento: \(K \log_{2}(N)\)
Número de saltos: \(\log_{2}(N)\)
Aplicación
Cuando se inicia Jami, cada conversación inicia la creación de su tabla de enrutamiento. El primer paso es establecer contacto con un primer nodo para comenzar la sincronización con otros nodos. Este proceso se conoce como «bootstrapping» y consta de dos partes principales.
La primera parte implica recuperar todos los dispositivos conocidos en una conversación. Esto se logra verificando certificados conocidos en el repositorio o verificando la presencia de ciertos miembros en la DHT (Tabla Hash Distribuida). Si ya existe una conexión TCP con cualquier dispositivo en la conversación, se utilizará. Además, los nodos conocidos se inyectan en la tabla de enrutamiento. Si ninguna conexión es exitosa, intenta encontrar nuevos dispositivos realizando una solicitud » GET » en el DHT para obtener dispositivos para cada miembro.
La tabla de enrutamiento se actualiza posteriormente cada vez que ocurre un evento en un nodo.
Durante las actualizaciones de la tabla de enrutamiento, el componente intentará establecer conexiones con nuevos nodos si es necesario. La decisión de conectarse a nuevos nodos se determina por las siguientes condiciones:
Para el depósito más cercano, se realiza un intento de conexión si \((\mathrm{maxSize}(\mathrm{bucket}) - \mathrm{connectedNodes} - \mathrm{connectingNodes}) > 0\).
Para otros buckets, se inicia una conexión si \((\mathrm{maxSize}(\mathrm{bucket}) - \mathrm{connectingNodes}) > 0\).
La distinción radica en el hecho de que, en el caso del cubo más cercano, el objetivo es intentar dividir los cubos si es necesario, al mismo tiempo que se compensa por las desconexiones en otros cubos. Esto es esencial para mantener el conocimiento de los nodos más cercanos.
Al conectarse a un nuevo nodo, se envía una solicitud «FIND» para descubrir nuevos identificadores cercanos e identificar todos los nodos móviles. Posteriormente, se envía una solicitud «FIND» cada diez minutos para mantener actualizada la tabla de enrutamiento.
La clase principal responsable de este proceso en la base de código es SwarmManager, y la fase de arranque se maneja dentro de la sección de conversación.
Arquitectura
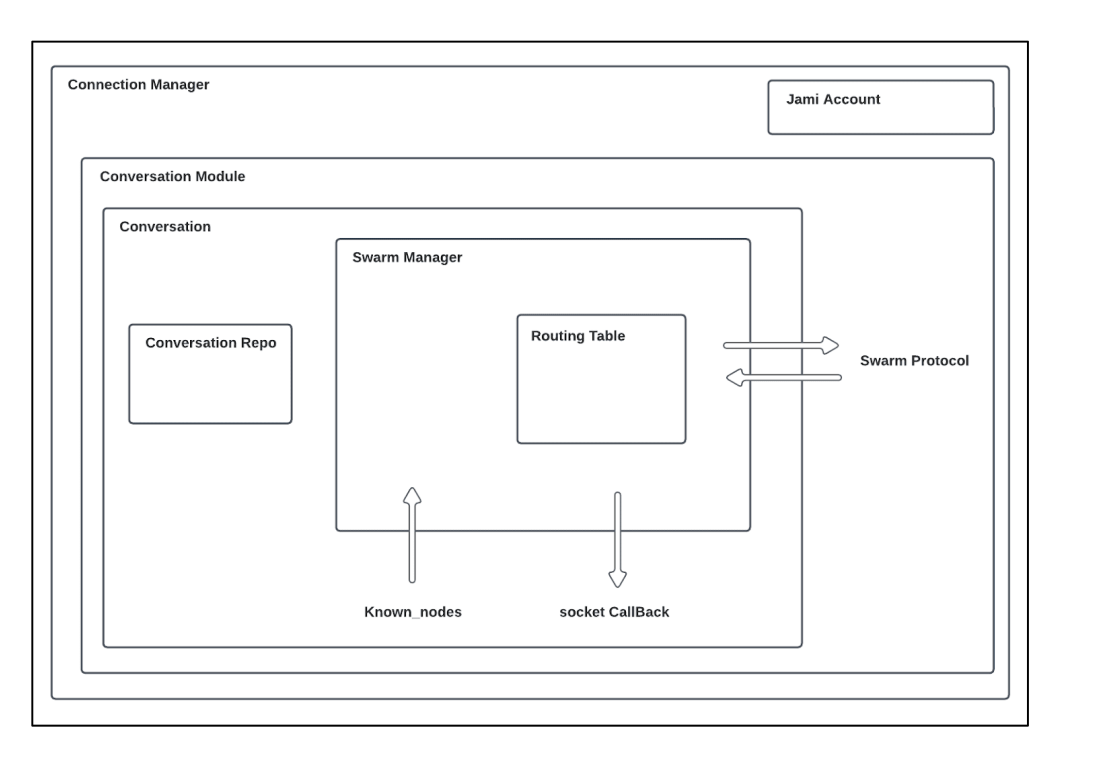
Análisis de rendimiento
Herramientas
Para validar la implementación y el rendimiento del componente DRT, se han desarrollado varias herramientas que se encuentran en “daemon/tests/unitTest/swarm”, incluidas “swarm_spread”, “bootstrap” y más.
Para interpretar los resultados, se utilizan las siguientes herramientas:
gcovpara análisis de cobertura de pruebas.ASanpara verificar fugas de memoria y desbordamientos de montón.gdbpara depurar estructuras internas.
Si bien el enfoque principal está en las pruebas unitarias, para el análisis de rendimiento, se confía en `swarm_spread” para evaluar varios aspectos, que incluyen:
El número de saltos requeridos para la transmisión del mensaje.
El número de mensajes recibidos por nodo.
Determinar los mensajes máximos y mínimos recibidos por cada nodo.
Calculando las iteraciones necesarias para transmitir un mensaje a todos los nodos.
Medición de los tiempos de recepción de mensajes.
Resultados
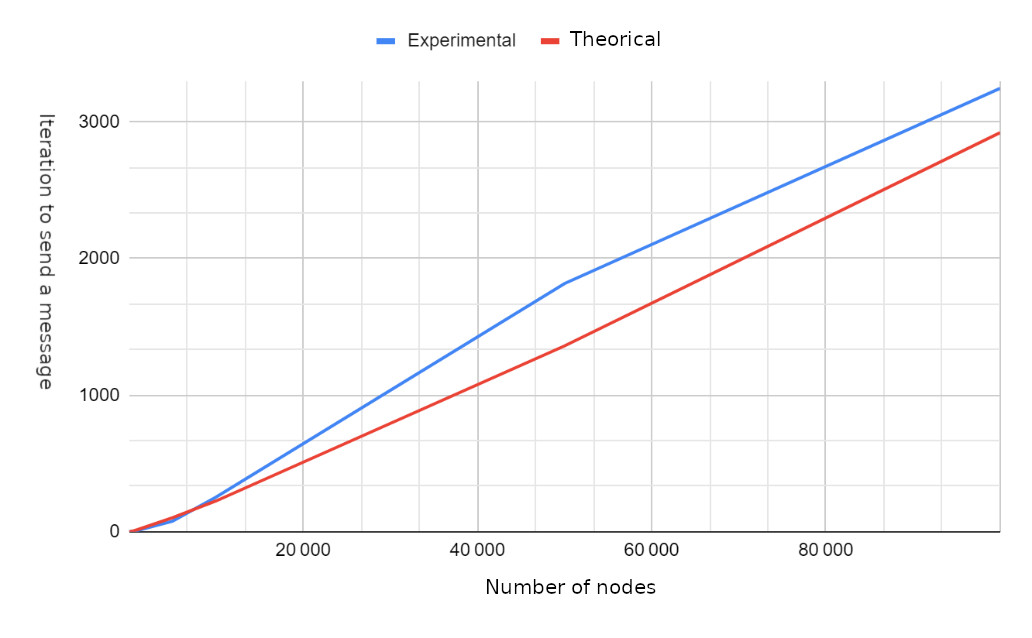
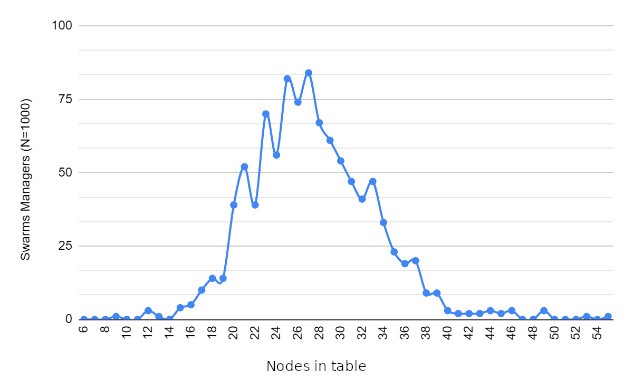
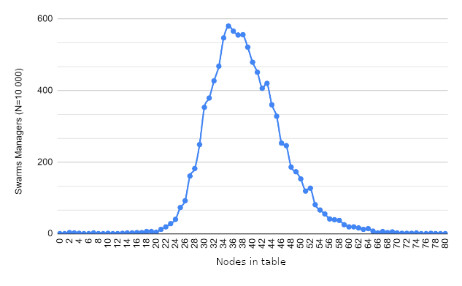
Trabajo futuro
Límite dinámico de tamaño de depósito para obtener diferentes tamaños de depósito según el tamaño de la tabla de enrutamiento.
Declinando algunas conexiones para acelerar un poco la transmisión.